Hello world
In this tutorial, we’ll walk you through the process of setting up Gruntwork Pipelines for a single AWS account. This is useful both as a "hello world" for Gruntwork Pipelines and as the first step to getting it ready for production.
What you'll get
By the end, you’ll have:
- An automated pipeline for deploying infrastructure changes into an AWS account
- Two GitHub repositories
infrastructure-live— Defines the infrastructure that is deployed to your AWS accountinfrastructure-pipelines— Contains deployment definitions for your infrastructure
- An IAM role in your AWS account that allows GitHub Actions to assume a role in your AWS account using OIDC
- An S3 Bucket deployed automatically by Gruntwork Pipelines
Prerequisites
Before you begin, make sure you have:
- Permissions to create and administer repositories in GitHub
- A sandbox or development AWS account
- Valid AWS credentials for a user with AdministratorAccess to the AWS account mentioned above
- Boilerplate installed on your system (requires Gruntwork subscription)
- Terragrunt installed on your system
- A classic GitHub PAT with
repoandworkflowscopes and access to Gruntwork modules
To create a classic GitHub PAT, go to https://github.com/settings/profile, click on Developer Settings, then Personal access tokens, then Tokens (classic), then Generate new token (classic). In the "Note" field, enter "Gruntwork Pipelines POC" (or something similar), select the repo and workflow scope checkboxes, then click Generate token. Keep your token handy; we'll be using it shortly.
Setting up the repositories
First, you’ll set up two git repositories:
- The
infrastructure-liverepository will contain the definitions of your infrastructure as code (IaC) - The
infrastructure-pipelinesrepository will define how your IaC will be deployed.
Then, you’ll create a GitHub Personal Access Token (PAT) that allows:
- GitHub Actions (GHA) workflows defined in
infrastructure-liveto run GHA workflows defined ininfrastructure-pipelines - GHA workflows defined in
infrastructure-pipelinesto clone theinfrastructure-liverepository
Finally, you’ll set up your PAT as a GitHub Actions secret in each repository.
Create the repositories
In this tutorial, we will use the default GitHub repo configuration.
In a production environment, we recommend setting up
branch protection rules
for your main branch as described in Branch Protection.
Navigate to the repositories tab of your organization or personal GitHub account in your web browser. Repeat the following steps twice to create one repository named infrastructure-live and one repository named infrastructure-pipelines.
- Click the
New Repositorybutton. - In the
Repository namefield enter eitherinfrastructure-liveorinfrastructure-pipelines - Select the
Privateoption - Do not initialize the repo with a README, gitignore, or license
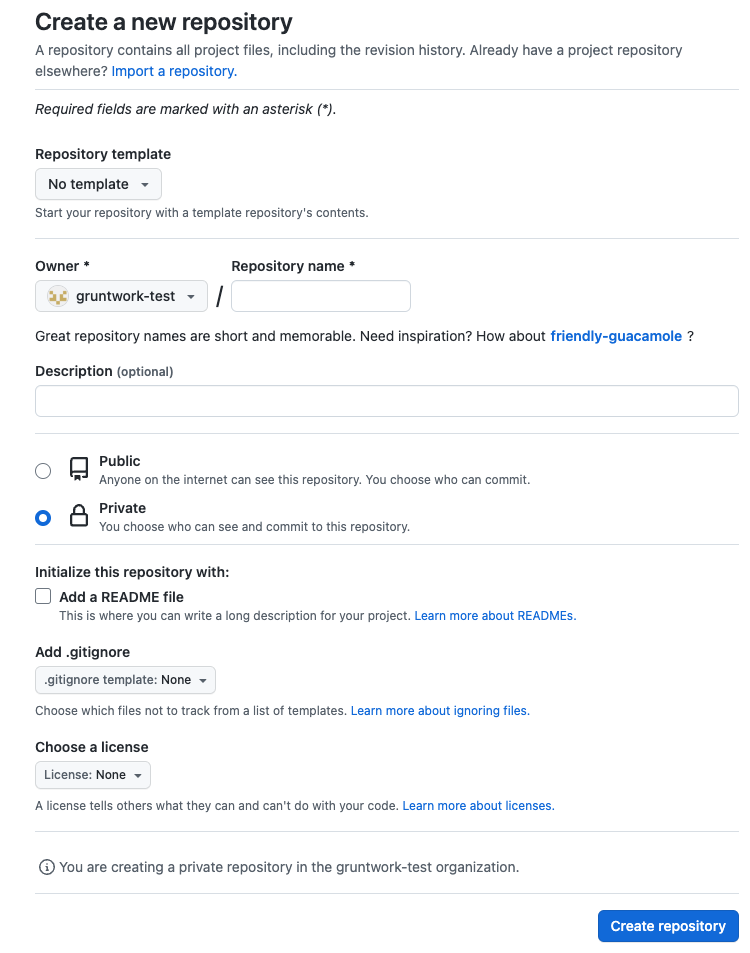 GitHub form for creating a new repository
GitHub form for creating a new repository
Setting up secrets
In this tutorial, we will use a single GitHub Personal Access Token (PAT) with broad access.
In a production environment, we recommend using a mix of fine-grained and classic PATs as described in Machine Users.
Next, you're going to configure GitHub Actions secrets for each repository. Our goal here is to enable:
infrastructure-liveto kick off GitHub Actions workflows in theinfrastructure-pipelinerepositoryinfrastructure-pipelinesto clone theinfrastructure-liverepositoryinfrastructure-pipelinesto access Gruntwork modules
First, navigate to the infrastructure-live repository. Select the Settings tab, select the Secrets and variables drop down on the left side panel, then select Actions. Create the following secrets and use your GitHub PAT as the value for all of them:
PIPELINES_DISPATCH_TOKENINFRA_LIVE_ACCESS_TOKENGRUNTWORK_CODE_ACCESS_TOKEN
Next, navigate to the infrastructure-pipelines repository. Select the Settings tab, select the Secrets and variables drop down on the left side panel, then select Actions. Create the following secrets and use your GitHub PAT as the value for all of them:
INFRA_LIVE_ACCESS_TOKENGRUNTWORK_CODE_ACCESS_TOKEN
Generating code
Next, you’ll write the IaC and GitHub Actions workflow code required to run Gruntwork Pipelines.
Rather than copy & pasting this code from documentation, we're going to generate the code using Boilerplate, a code generation tool authored by Gruntwork. The generated code will:
- Provision an AWS IAM role (which Pipelines will assume to manage AWS resources)
- Configure one GitHub Actions (GHA) workflow for the
infrastructure-liverepository - Configure one GHA workflow for the
infrastructure-pipelinesrepository
The code generation template for infrastructure-live sets up a folder structure that follows Gruntwork’s recommended folder structure for Terragrunt, so you could continue to use the generated code in perpetuity and simply add more AWS accounts and resource definitions if you so choose!
Infrastructure-pipelines
First, generate the infrastructure-pipelines repository code using Boilerplate. On your local computer, git clone the newly created infrastructure-pipelines repository, cd into the repo directory, then use the following command replacing <your GitHub organization name> with the name of your GitHub organization.
boilerplate --template-url "github.com/gruntwork-io/terraform-aws-architecture-catalog.git//blueprints/components/infrastructure-pipelines?ref=devops-foundations" \
--output-folder . \
--var InfraLiveRepoName="infrastructure-live" \
--var GithubOrg="<your GitHub organization name>" \
--non-interactive
Push your changes to the infrastructure-pipelines repository you created in Create the repositories.
Infrastructure-live
Next, generate the infrastructure-live repository code using Boilerplate. On your local computer, git clone the newly created infrastructure-live repository, cd into the repo directory, then use the following command, replacing the values wrapped in <> with real values for your organization.
The AWSAccount* variables correspond to the AWS account in which your infrastructure-live repository will manage AWS resources. The OrgNamePrefix is used to prefix your resource names with your org name so that they are identifiable. For example, we will create an S3 bucket to store Terraform/OpenTofu state, whose name begins with the value of OrgNamePrefix.
boilerplate --template-url "github.com/gruntwork-io/terraform-aws-architecture-catalog.git//blueprints/components/single-account-pipeline?ref=devops-foundations" \
--output-folder . \
--var AwsAccountName="<friendly name for your AWS account (e.g., dev)>" \
--var AwsAccountId="'<account id for your AWS account>'" \
--var AwsAccountEmail="<e-mail address associate with root user for account>" \
--var InfraLiveRepoName="infrastructure-live" \
--var InfraPipelinesRepoName="infrastructure-pipelines" \
--var GithubOrg="<your GitHub organization name>" \
--var OrgNamePrefix="<your organization name>" \
--var RequestingTeamName="<The name of the team that will use the pipeline>" \
--non-interactive
The generated code creates a full Terragrunt infrastructure-live folder structure that creates a single AWS resource, which is an AWS IAM role that Pipelines will use to deploy resources in your AWS account. More specifically, it will create an instance of the Gruntwork github-actions-iam-role module, which creates an IAM role that is assumable by GitHub using OIDC, and which can only be assumed when running a GitHub Actions workflow from the main branch.
With Pipelines, all terragrunt operations will happen in GitHub Actions in response to a Pull Request or git push. But before that will work, you will first need to run an apply locally to provision the IAM role. This should be the only time you need to manually run apply to provision resources for this account, moving forward Pipelines will handle the lifecycle of all resources for you, based on the code you commit to your repository.
First, run a run-all plan in the newly created directory named after the account to see the resources that will be provisioned. Replace <account name> with the value you used for AwsAccountName in the boilerplate command above.
cd <account name>/
terragrunt run-all plan
Terragrunt will prompt you to create the Terragrunt state and logs buckets, enter y when prompted, then hit enter.
Terragrunt will then run the plan. Once you have reviewed the new resources to be created, run terragrunt run-all apply to create the resources.
Finally, git push your changes to the infrastructure-live repository you created in Create the repositories.
Running your first pipeline
Next you’ll create a resource in your AWS account using Pipelines and GitOps workflows. You’ll define a terragrunt.hcl file that creates an AWS S3 bucket in your AWS account, push your changes and create a pull request (PR) to run a plan action, then run an apply action to create the bucket by merging your PR.
Adding a new S3 bucket
First, create the folder structure that will contain the new S3 bucket in your environment. Replace <account name> with the value you used for AwsAccountName when generating your infrastructure-live code in the infrastructure live section.
mkdir -p <account name>/<region>/<account name>/data-storage/s3
touch <account name>/<region>/region.hcl
touch <account name>/<region>/<account name>/data-storage/s3/terragrunt.hcl
Add the following content to the region.hcl file created above, replacing <your region> with the region you would like to deploy infrastructure in.
locals {
aws_region = "<your region>"
}
Next, add the terragrunt code to create an S3 bucket. Copy the terragrunt code below, replacing <your S3 bucket name> with your desired bucket name. S3 bucket names need to be globally unique, so we've provided a helper script below to help generate the name of your bucket. You may name the bucket whatever you like, just make sure it’s unique.
export export UNIQUE_ID=$(uuidgen | tr 'A-Z' 'a-z')
export DATE_NOW=$(date "+%F")
echo "gwp-bucket-${UNIQUE_ID}-${DATE_NOW}"
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK’s S3-BUCKET MODULE
# ------------------------------------------------------------------------------------------------------
terraform {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/data-stores/s3-bucket?ref=v0.104.15"
}
include "root" {
path = find_in_parent_folders()
}
inputs = {
primary_bucket = "<your S3 bucket name>"
}
Planning and Applying
Create a new branch for your changes, commit your changes to your branch, then push your branch. Next, create a PR to merge your branch into main (the default branch in your repository). Follow this GitHub tutorial to create a pull request using your preferred tool of choice.
After you create the PR, GitHub Actions (GHA) will automatically run the GHA workflow defined in infrastructure-live in /.github/workflows/pipelines.yml. Once complete, Pipelines will add a comment to the PR with a link to the GHA workflow logs, click the link see the output of the terragrunt plan action that ran as a result of your changes.
If the plan output looks as expected, you are ready to merge your PR and create the S3 bucket. Click the Merge pull request button to merge the pull request. On merge, Pipelines will automatically run an apply action to provision the S3 bucket. You can find the GHA workflow run associated with the merged PR by navigating to the main branch on your PR and clicking on the Check Run icon at the top of the file explorer, then clicking details next to the Pipelines workflow. This will take you to the dispatch job for Pipelines, which contains a link to the workflow run in infrastructure-pipelines where you can see the output of your Pipelines run.
Congratulations! You've just used Gruntwork Pipelines and a GitOps workflow to provision resources in AWS.
Common errors
Error: Parameter token or opts.auth is required
This means that one of the secrets you needed to specify above was not configured correctly.
Next steps
Add/update/destroy more resources
At this point, you can continue using Pipelines on your own by adding, updating, and deleting terragrunt.hcl files to or from your environment. Alternatively, create a _module_defaults directory as a way to set default module vaules picked up by multiple terragrunt.hcl files, define a module there, then use it in your environment to see how Pipelines handles these types of changes.
Adding more AWS accounts
You also can extend your usage across many AWS accounts by re-running the infrastructure-live boilerplate template to create the folder structure for additional accounts (you will need to manually update your accounts.yml file with this approach).
Adding more git repositories
You can extend the Pipelines model so that a single infrastructure-pipelines repository can serve more than one infrastructure-live repository. This is useful if a central DevOps team or platform team wants to maintain control over the Pipeline, while allowing individual app teams to "hook in" to the Pipeline.
Cleanup (optional)
If you are not going to continue using Pipelines after this tutorial, clean up the resources you created by running terragrunt run-all destroy from your account based folder. You may also delete the two repositories created in Setting up the repositories.